












Introducción a GPU Computing
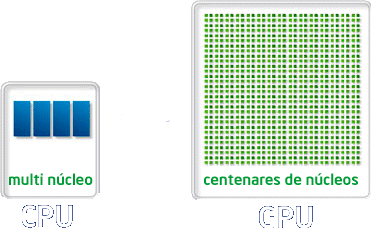 La gran novedad de la computación por GPU de NVIDIA es la posibilidad de usar los procesadores de la tarjeta gráfica para realizar cálculo paralelo por medio de la tecnología CUDA. Los sistemas informáticos hasta la actualidad estaban pensados para realizar todos los cálculos de procesamiento con el microprocesador integrado en placa (como por ejemplo Intel Core i7, i5, i3 o un microprocesador de AMD entre otros). Gracias a la arquitectura de cálculo paralelo CUDA inventada por NVIDIA es posible realizar cálculos tanto con el CPU (procesador del ordenador integrado en la placa base) como con GPU (procesador gráfico integrado dentro de las tarjetas gráficas). Es por tanto posible realizar “coprocesamiento” repartido entre la CPU y la GPU.
La gran novedad de la computación por GPU de NVIDIA es la posibilidad de usar los procesadores de la tarjeta gráfica para realizar cálculo paralelo por medio de la tecnología CUDA. Los sistemas informáticos hasta la actualidad estaban pensados para realizar todos los cálculos de procesamiento con el microprocesador integrado en placa (como por ejemplo Intel Core i7, i5, i3 o un microprocesador de AMD entre otros). Gracias a la arquitectura de cálculo paralelo CUDA inventada por NVIDIA es posible realizar cálculos tanto con el CPU (procesador del ordenador integrado en la placa base) como con GPU (procesador gráfico integrado dentro de las tarjetas gráficas). Es por tanto posible realizar “coprocesamiento” repartido entre la CPU y la GPU.
La gama de equipos HPC MANTIS ha sido desarrollada teniendo en cuenta el gran potencial que tienen las recientes aportaciones de NVIDIA a diversos campos profesionales como procesamiento de vídeo, la astrofísica, la biología y la química computacional, la simulación de mecánica de fluidos, la interferencia electromagnética, la reconstrucción de imágenes de TC, el análisis sísmico o el trazado de rayos entre otras.
Por tanto la novedad es que mientras que un microprocesador actual de Intel o AMD tiene hasta 4 ó 6 núcleos, que pueden ser hasta 12 con la tecnología de Intel HyperThreading, los procesadores gráficos de las tarjetas de NVIDIA tienen hasta 512 núcleos de procesamiento paralelo. La capacidad de procesamiento desde 12 núcleos a 512 aumenta el rendimiento y las capacidades de computación de forma impresionante.
GPU Computing es por tanto es el uso de la GPU (unidad de procesamiento gráfico) para realizar operaciones de cálculo científico o técnico de propósito general. El modelo empleado para esta tecnología se basa en el uso combinado de una CPU y una GPU en un sistema de coprocesamiento heterogéneo. La parte secuencial de la aplicación se ejecuta en la CPU y las partes de mayor carga computacional se aceleran en la GPU. Para el usuario, la aplicación simplemente se ejecuta más rápido porque utiliza la gran capacidad de la GPU para multiplicar el rendimiento.
 Configuración icosaédrica de la cápside del virus STM. |
A lo largo de los años, la GPU ha evolucionado hasta alcanzar Teraflops de rendimiento en las operaciones de cálculo en coma flotante. NVIDIA revolucionó la GPGPU y aceleró el mundo de la informática durante los años 2006-2007 con la introducción de su arquitectura de cálculo paralelo masivo “CUDA”. Esta arquitectura consta de cientos de núcleos de procesamiento que operan de forma conjunta para manejar los datos de la aplicación a mayor velocidad.
El éxito de las GPUGPUs en los últimos años reside en la facilidad del modelo de programación paralela CUDA asociado. En este modelo, el desarrollador de la aplicación modifica ésta para asignar a la GPU los kernels más complejos desde el punto de vista computacional. El resto de la aplicación permanece en la CPU. Asignar una función a la GPU implica reescribir ésta para aprovechar el paralelismo del procesador gráfico y agregar palabras clave de “C” para transferir los datos hacia y desde la GPU. El programador se encarga de lanzar decenas de miles de procesos (threads) de forma simultánea. El hardware de la GPU maneja estos procesos y programa su ejecución.
![]() La GPU Tesla Serie 20 se basa en la nueva arquitectura “Fermi”, que es la tercera generación de la arquitectura CUDA. Fermi está optimizada para acelerar las aplicaciones científicas en la GPU, con aspectos clave tales como un rendimiento de más de 500 gigaflops en operaciones de coma flotante de precisión doble según la norma IEEE, memoria caché L1 y L2, memoria con protección de errores ECC, cachés locales administradas por el usuario y formadas por memoria compartida distribuida por toda la GPU, acceso coalescente a la memoria, etc.
La GPU Tesla Serie 20 se basa en la nueva arquitectura “Fermi”, que es la tercera generación de la arquitectura CUDA. Fermi está optimizada para acelerar las aplicaciones científicas en la GPU, con aspectos clave tales como un rendimiento de más de 500 gigaflops en operaciones de coma flotante de precisión doble según la norma IEEE, memoria caché L1 y L2, memoria con protección de errores ECC, cachés locales administradas por el usuario y formadas por memoria compartida distribuida por toda la GPU, acceso coalescente a la memoria, etc.
*Fuentes: NVIDIA Corporation.
Tarjetas NVIDIA Tesla
 La arquitectura de cálculo paralelo NVIDIA® CUDA™ esta activada en los productos GeForce®, Quadro® y Tesla™. Mientras que GeForce y Quadro se han diseñado para gráficos de consumo y visualización profesional respectivamente, la familia de productos Tesla se ha diseñado para el cálculo paralelo y ofrece funciones de computación exclusivas. Las principales ventajas de las tarjetas Tesla frente a Quadro o GeForce son: Rendimiento completo de doble precisión, Comunicación PCIe más rápida y Soporte de grandes volúmenes de datos. Además el driver de las tarjetas Tesla para el sistema operativo Windows 7 está optimizado para todas las aplicaciones de uso profesional, incluye el software NVIDIA GPUDirect™ con InfiniBand.
La arquitectura de cálculo paralelo NVIDIA® CUDA™ esta activada en los productos GeForce®, Quadro® y Tesla™. Mientras que GeForce y Quadro se han diseñado para gráficos de consumo y visualización profesional respectivamente, la familia de productos Tesla se ha diseñado para el cálculo paralelo y ofrece funciones de computación exclusivas. Las principales ventajas de las tarjetas Tesla frente a Quadro o GeForce son: Rendimiento completo de doble precisión, Comunicación PCIe más rápida y Soporte de grandes volúmenes de datos. Además el driver de las tarjetas Tesla para el sistema operativo Windows 7 está optimizado para todas las aplicaciones de uso profesional, incluye el software NVIDIA GPUDirect™ con InfiniBand.
En la página de NVIDIA dedicada a Tesla podemos ver ejemplos de soluciones de Software con Tesla para diversos campos de la industria: http://www.nvidia.es/page/tesla_computing_solutions.html
Los procesadores de las tarjetas NVIDIA CUDA presenta ciertas ventajas sobre otros tipos de computación sobre GPU utilizando APIs gráficas. CUDA intenta aprovechar el gran paralelismo, y el alto ancho de banda de la memoria en las GPUs en aplicaciones con un gran coste aritmético frente a realizar numerosos accesos a memoria principal, lo que podría actuar de cuello de botella. El modelo de programación de CUDA está diseñado para que se creen aplicaciones que de forma transparente escalen su paralelismo para poder incrementar el número de núcleos computacionales. Este diseño contiene tres puntos claves, que son la jerarquía de grupos de hilos, las memorias compartidas y las barreras de sincronización. La estructura que se utiliza en este modelo está definido por un grid, dentro del cual hay bloques de hilos que están formados por como máximo 512 hilos distintos. Cada hilo está identificado con un identificador único, que se accede con la variable threadIdx. Esta variable es muy útil para repartir el trabajo entre distintos hilos. threadIdx tiene 3 componentes (x, y, z), coincidiendo con las dimensiones de bloques de hilos. Así, cada elemento de una matriz, por ejemplo, lo podría tratar su homólogo en un bloque de hilos de dos dimensiones. Al igual que los hilos, los bloques se identifican mediante blockIdx (en este caso con dos componentes x e y). Otro parámetro útil es blockDim, para acceder al tamaño de bloque.
Sistemas de Computación MANTIS
Le ofrecemos toda una extensa gama de estaciones de computación con tarjetas NVIDIA Tesla C2075, M2075 y M2090 de PNY integradas en ordenadores pensados para la potencia y para muy alto rendimiento. Todos los componentes de estos equipos están pensados y escogidos con tal fin: Gran potencia en todos los sentidos, un equipo fiable y estable que aguantará muchos años. Todos los componentes son de primeras marcas y tienen garantías de 10 años para las placas base, 3 años los procesadores o garantía de por vida las memorias. Puede comprobar en este enlace cuál es nuestra filosofía de trabajo y cómo montamos nuestros equipos con todo lujo de detalles garantizándole la gran potencia, estabilidad y baja sonoridad del mismo, desde la elección de los componentes, el montaje, las pruebas de estabilidad, test de rendimiento y una cuidada atención al cliente post-venta.