












Una novedosa tecnología que inaugura una nueva era de productividad para millones de profesionales del diseño y la creatividad.

NVIDIA anunció recientemente su tecnología NVIDIA® Maximus™, algo que los profesionales de la visualización, animación, 3D, edición de vídeo, etc. llevan esperando desde hace más de 25 años. Una estación de trabajo con las capacidades de computación de un superordenador que pueda procesar de forma simultanea análisis complejos y visualización.
Todos estos profesionales de la visualización desearían tener la potencia de cómputo de un superordenador para su trabajo, pero salvo el caso de grandes empresas que disponen de estos, los superordenadores no están al alcance de cualquiera. Ahora NVIDIA con esta tecnología pone a disposición de todos estos profesionales esa potencia de cálculo dentro de una estación de trabajo.

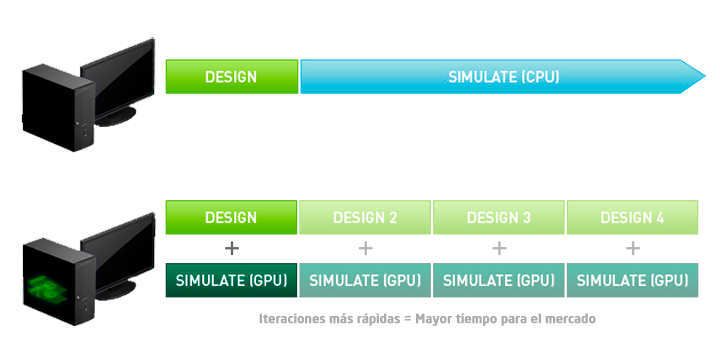
Ésta nueva solución desata la productividad y creatividad, acelerando considerablemente el flujo de trabajo de los profesionales creativos al habilitar por primera vez en un solo sistema la capacidad de manejar de forma simultanea gráficos interactivos y el procesamiento numérico de gran carga computacional asociado con la simulación o procesamiento de resultados. Estas tareas debían ser ejecutadas de forma separada en pasos separados (por las noches, durante la comida, etc.) o en sistemas diferentes.
Todo esto se traduce en conseguir la capacidad de mostrar una animación, un diseño 3D, edición de vídeo con efectos o cualquier otra visualización que requiera de complejos cálculos para mostrarse, en tiempo real.
Hasta ahora todos los profesionales de este sector han padecido y padecen las largas esperas que requiere un buen renderizado, y más aún si este es complejo y utiliza técnicas como el trazado de rayos, etc. En el caso de la edición de vídeo, y más aún en alta definición, el procesar los efectos de una secuencia que se compone de muchas imágenes requiere también de mucho proceso que lleva mucho tiempo, al igual que la conversión y codificación en diferentes formatos (MPG4, blu-Ray, etc.). Ahora y gracias a esta tecnología NVIDIA® Maximus™ conseguiremos renderizados en tiempo real y aquellos más complejos que tardaban horas e incluso días, se podrán conseguir en apenas unos minutos al igual que los renderizados de los efectos en la edición de vídeo en alta definición también en tiempo real y la codificación de formatos de vídeo en apenas unos minutos.
¿Se imagina conseguir un efecto visual, una imagen 3D renderizada en tiempo real?
Como una imagen vale más que mil palabras, antes de entrar en detalles, y para entender claramente esta tecnología y lo que queremos explicar, hay que ver el siguiente vídeo de presentación de esta tecnología por NVIDIA, y la demostración en tiempo real de una animación con el programa Autodesk Maya.
Más adelante en este artículo, mostraremos vídeos con más ejemplos de como afecta esta tecnología a otras aplicaciones como Adobe Premiere, Autodesk 3ds Max, etc. así como gráficos con el incremento del rendimiento en estas aplicaciones utilizando esta tecnología NVIDIA® Maximus™.
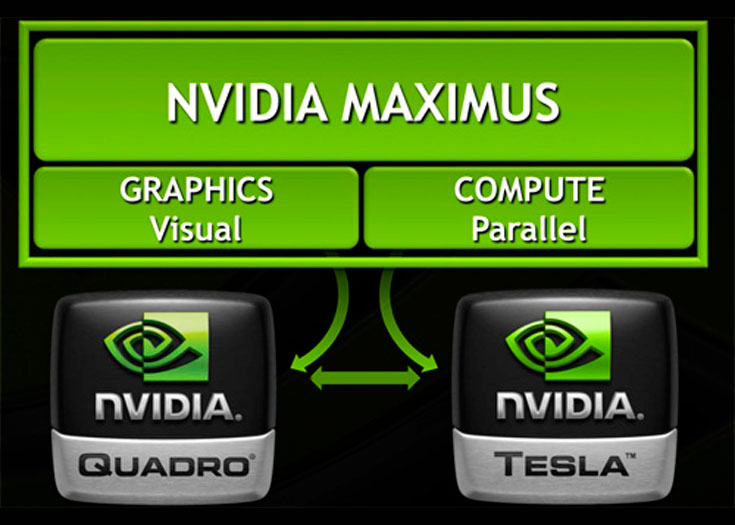
NVIDIA® Maximus™ logra todo esto al unir las capacidades de gráficos profesionales 3D de las unidades de procesamiento gráfico profesionales NVIDIA Quadro® (GPU, por sus siglas en inglés) con el poder masivo de procesamiento paralelo de la GPU acompañante, NVIDIA Tesla™ C2075 bajo una tecnología unificada que asigna de forma transparente el trabajo a cada procesador y está certificada por los proveedores de las aplicaciones líderes en la industria.
Comenta Jeff Brown, gerente general, Grupo de Soluciones Profesionales, NVIDIA:
"Para aquellos de nosotros que hemos puesto todo el foco de nuestras carreras en las estaciones de trabajo, NVIDIA® Maximus™ representa una revolución. La arquitectura previa de estaciones de trabajo forzaba a los diseñadores e ingenieros a realizar toda la tarea de cómputo pesada y la tarea intensa en gráficos de forma serial y con frecuencia en sistemas separados. Ahora pueden hacerlo al mismo tiempo, en el mismo equipo, lo que le permite a los profesionales explorar más ideas de forma más rápida y converger en menor tiempo en las mejores respuestas posibles."
Con aplicaciones habilitadas para NVIDIA® Maximus™, como las de Adobe, ANSYS, Autodesk, Bunkspeed, Dassault Systèmes y MathWorks, el trabajo de cómputo en GPU se asigna para trabajar directamente en la GPU acompañante, NVIDIA Tesla. Esto libera la GPU NVIDIA Quadro para que pueda manejar funciones gráficas, asegurando la calidad y rendimiento que los usuarios profesionales demandan.
Comenta Tim Ong, vice presidente de Ingeniería Mecánica para Liquid Robotics:
"La verdadera ventaja de la tecnología Maximus es la flexibilidad y productividad mejorada. El permitirle a cada ingeniero el hacer múltiples cosas al mismo tiempo transforma nuestro flujo de trabajo. Es una gran herramienta que le permite a mis ingenieros ser flexibles, multi-tareas, y ser más productivos porque no se quedan cortos en poder de cómputo.

¿Qué es exactamente NVIDIA® Maximus™?

NVIDIA® Maximus™ es una interesante tecnología que permite a los clientes combinar Tesla y Quadro juntos en una sola estación de trabajo y utilizar sus respectivas capacidades y potencia. No es un producto nuevo, es una nueva tecnología, una nueva forma de utilizar las tarjetas Quadro de NVIDIA existentes y los productos Tesla juntos. Dicho de otra manera para entenderlo, funciona en la misma línea que Optimus™, otra tecnología de controlador de NVIDIA para permitir la combinación transparente de GPU para portátiles con Intel IGP, pues Maximus™ es una tecnología de controlador para permitir la combinación transparente de Quadro de NVIDIA con los productos Tesla. También se podría comparar en menor medida con la tecnología SLI de NVIDIA que consigue multiplicar la potencia de una tarjeta gráfica GeForce para juegos añadiendo hasta 4 tarjetas gráficas y con un controlador que se encarga de repartir las cargas de trabajo entre ellas.
Maximus™ está dispuesta a ofrecer algunas cosas diferentes, todas los cuales vienen de nuevo a un solo concepto: la utilización de las tarjetas Quadro y Tesla, junto a las tareas que están más adecuadas en cada caso. Esto significa el uso de tarjetas Quadro para las tareas gráficas y simultáneamente el uso de Tesla para las tareas de cómputo, donde la representación gráfica directa no es necesaria. En última instancia, esto parece un concepto extraño al principio ya que las tarjetas Quadro de gama alta son totalmente capaces de realizar las tareas de cómputo y de cálculos complejos. De hecho la tarjeta Quadro 6000, la más alta de gama, es similar en capacidades técnicas, procesadores, núcleos, etc. que la tarjeta Tesla. Pero todo esto empieza a cobrar sentido si nos fijamos en las actuales limitaciones técnicas del hardware de NVIDIA, y más aún en los casos que estamos proponiendo aquí con la tecnología Maximus™.
Combinando Quadro y Tesla: Los detalles técnicos.
La base fundamental de la tecnología Maximus™ son los controladores de NVIDIA. Hasta antes de que se presentara esta tecnología, los controladores de NVIDIA Quadro y los controladores de NVIDIA Tesla eran distintos, independientes. Para que funcione esta tecnología es necesario que vayan unidos, en un solo controlador que funcione tanto para las Quadro como para las Tesla. NVIDIA lleva utilizando desde hace mucho años, una base de código compartido para todos sus controladores, por lo que Tesla y Quadro (y GeForce) contenía ese código compartido, pero el problema era que ese código necesitaba funcionar conjuntamente. Esto es más difícil de lo que parece ya que mientras que los controladores Quadro son bastante sencillos, renderizados gráficos sin acceso a todos los rendimientos y con acceso a las características más extrañas como como las fuentes de sincronización externas, Tesla sin embargo ofrece un gran número de optimizaciones únicas, principalmente en el controlador “Tesla Computer Cluster”, que se trasladó a Windows como un dispositivo de gráficos.
Todo este problema tuvo que ser resulto y el resultado fue que NVIDIA finalmente fue capaz de fusionar la base de código nuevo en un solo controlador para Quadro y Tesla en julio de 2.011 con los controladores con número de versión 275.xx.
Pero esto no se trata sólo de la combinación de las bases del código del controlador. Hacer el trabajo de Tesla y Quadro en una sola estación de trabajo resuelve los problemas de hardware, pero deja intacto y no soluciona el lado del software, es decir, de las aplicaciones. Desde hace algún tiempo los desarrolladores de CUDA, el entorno de desarrollo de NVIDIA para procesar en sus tarjetas, en un sistema con múltiples tarjetas con soporte CUDA, han sido capaces de seleccionar a cual dispositivo se envía una determinada tarea de cálculo, siendo esto siempre por definición un paso adicional para el desarrollo. Los desarrolladores o programadores tenían que trabajar para que su aplicación diera soporte a sistemas con múltiples dispositivos CUDA, y en la mayoría de los casos siempre era necesario exponer controles para los usuarios con el fin de que estos realizaran las asignaciones finales.
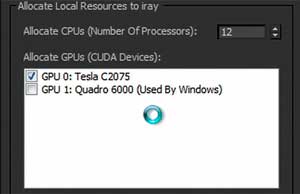 Esto significa en primer lugar que la aplicación tiene que estar programada en concreto para soportar varias tarjetas, y segundo que el usuario tiene que asignar manualmente estas tarjetas, como muestra la siguiente imagen de una conocida aplicación donde hay que indicarle manualmente las tarjetas que va utilizar dicha aplicación. Esto funciona bastante bien en manos de usuarios expertos, pero la estrategia de NVIDIA CUDA ha sido siempre la de empujar CUDA más y más profundo en el mundo con el fin de hacerlo más omnipresente, y esto significa que siempre tiene que ser fácil de usar. Y más aún con esta tecnología Maximus™ que está no está pensada para usuarios expertos en informática, sino para usuarios y profesionales expertos en la visualización, animación, 3D, edición de vídeo, etc.
Esto significa en primer lugar que la aplicación tiene que estar programada en concreto para soportar varias tarjetas, y segundo que el usuario tiene que asignar manualmente estas tarjetas, como muestra la siguiente imagen de una conocida aplicación donde hay que indicarle manualmente las tarjetas que va utilizar dicha aplicación. Esto funciona bastante bien en manos de usuarios expertos, pero la estrategia de NVIDIA CUDA ha sido siempre la de empujar CUDA más y más profundo en el mundo con el fin de hacerlo más omnipresente, y esto significa que siempre tiene que ser fácil de usar. Y más aún con esta tecnología Maximus™ que está no está pensada para usuarios expertos en informática, sino para usuarios y profesionales expertos en la visualización, animación, 3D, edición de vídeo, etc.
Esto nos trae de vuelta a Optimus™. El objetivo de la tecnología Optimus™ de NVIDIA fue reemplazar manualmente la combinación de los flujos de datos de las GPUs en un solo flujo con un sistema totalmente transparente para que los usuarios no tuvieran que realizar ninguna configuración ni paso adicional para poder utilizar su tarjeta gráfica GeForce para portátil con conjunción la tarjeta gráfica IGP de Intel integrada en el procesador, ni preocuparse por que tarjeta gráfica estaba utilizando el sistema en cualquier momento. Optimus™ tendría, y tiene cuidado de enviar todas las cargas ligeras de trabajo a la tarjeta IGP de Intel, mientras que las cargas más pesadas y significativas como las de los juegos, etc. sean enviadas a la GPU de NVIDIA.
 Maximus™ encarna un concepto muy similar a este, excepto que con Optimus™ se trata de calcular la asignación de cargas de trabajo de forma transparente para el uso adecuado de GPU. Con una base unificada de controladores para Quadro y Tesla, los controladores de NVIDIA pueden presentar ambos dispositivos a una aplicación como dispositivos CUDA válidos. Maximus™ lleva esto a su conclusión lógica al tomar la iniciativa para dirigir el cálculo de las cargas de trabajo al dispositivo de Tesla, por lo que la asignación de CUDA al dispositivo o la tarjeta se convierte en una operación transparente para los usuarios y desarrolladores por igual, de la misma manera que la combinación de los flujos de datos de las GPUs en un solo flujo GPU en Optimus™. Además, las cargas de trabajo todavía se pueden controlar manualmente, pero al final, todos los desarrolladores acabaran despreocupándose de programar estas tareas y dejando que NVIDIA junto con su controlador se encargue de esto.
Maximus™ encarna un concepto muy similar a este, excepto que con Optimus™ se trata de calcular la asignación de cargas de trabajo de forma transparente para el uso adecuado de GPU. Con una base unificada de controladores para Quadro y Tesla, los controladores de NVIDIA pueden presentar ambos dispositivos a una aplicación como dispositivos CUDA válidos. Maximus™ lleva esto a su conclusión lógica al tomar la iniciativa para dirigir el cálculo de las cargas de trabajo al dispositivo de Tesla, por lo que la asignación de CUDA al dispositivo o la tarjeta se convierte en una operación transparente para los usuarios y desarrolladores por igual, de la misma manera que la combinación de los flujos de datos de las GPUs en un solo flujo GPU en Optimus™. Además, las cargas de trabajo todavía se pueden controlar manualmente, pero al final, todos los desarrolladores acabaran despreocupándose de programar estas tareas y dejando que NVIDIA junto con su controlador se encargue de esto.
Esto se explica mejor de la siguiente manera. Si nuestra aplicación o programa está realizando un complejo renderizado en tiempo real, esta aplicación tiene que tener la capacidad de procesar mucha información y cálculos complejos a la vez que muestra gráficamente el resultado en tiempo real. Anteriormente, si teníamos una tarjeta Quadro y una Tesla, la aplicación tenía que estar específicamente desarrollada para poder soportar ambas tarjetas, y además el usuario tenía que especificarle que disponía de esas dos tarjetas en su sistema para poder enviar dichos cálculos complejos a la tarjeta Tesla, mientras la tarjeta Quadro se encargaba de visualizar la imagen. Con Maximus™ el programador y el usuario de la aplicación o el programa pueden olvidarse de este tema, debido a que el nuevo controlador unificado detectará automáticamente y de forma transparente esos cálculos complejos que se encargará él solito de enviar a la tarjeta Tesla, al igual que se encargará de enviar todo el proceso de visualización a la tarjeta Quadro. Esto es realmente el potencial de toda esta tecnología.
Al igual que con Optimus™, los deseos de NVIDIA aquí son bastante sencillos: cuando algo es muy difícil de usar, más lenta es su adopción. Con Optimus™ ha hecho más fácil la integración de las tarjetas de NVIDIA en los ordenadores portátiles en conjunción con la tarjeta gráfica integrada dentro de los procesadores de Intel, y con Maximus™, será más fácil la adopción de CUDA en más aplicaciones y programas sin la necesidad de exigir a los programadores la realización de trabajos adicionales para la utilización de CUDA en varias tarjetas. Antes de Maximus™ se requería un gran trabajo adicional a los programadores, uno de los motivos para evitar o eludir la implementación de CUDA y una razón para que los compradores de hardware eviten comprar un producto de gama alta de NVIDIA si no tiene soporte por parte de los programas y las aplicaciones.
¿Por qué combinar Quadro y Tesla?.
 Hasta ahora hemos explicado de cómo NVIDIA Quadro y Tesla se combinan, pero la pregunta más interesante es, ¿por qué?
Hasta ahora hemos explicado de cómo NVIDIA Quadro y Tesla se combinan, pero la pregunta más interesante es, ¿por qué?
En la jerarquía de NVIDIA, Quadro es el producto líder de NVIDIA. Por la parte gráfica está totalmente desbloqueado, con el soporte de cuatro buffers, el rendimiento completo sin límites de geometría, y el rendimiento completo sin límites de visualización (viewport); mientras que en la parte de computación y cálculos ofrece soporte a velocidad completa de coma flotante a 64 bits (FP64). Además está disponible con las mismas configuraciones como una tarjeta Tesla, con el mismo número de núcleos CUDA y la misma memoria, por lo que, independientemente del controlador de Tesla, sí se puede calcular en una Tesla, se puede calcular en una Quadro.
Esto genera en realidad cierto grado de complejidad tanto para NVIDIA como para los usuarios. En un nivel técnico, el cambio de contextos de la tecnología Fermi (tecnología con la que están fabricadas y desarrolladas todas las tarjetas de NVIDIA) es relativamente rápido para una GPU, pero en un nivel absoluto sigue siendo lento. Los procesadores (CPUs) pueden cambiar de contextos en una fracción de tiempo, dando la impresión de un hilo de ejecución concurrente, incluso cuando sabemos que no es el caso. Además, por alguna extraña razón, el cambio de contextos entre un proceso de renderizado y un proceso de cálculos es particularmente costoso, lo que significa que se tiene que minimizar el número de cambios de contextos con el fin de evitar perder demasiado tiempo en el cambio de contexto.
Como resultado de todo esto y del tiempo necesario para cambiar el contexto, los productos Quadro no se adaptan bien en la realización de un renderizado y de cálculos complejos (computación) al mismo tiempo. Realmente puede, pero dependiendo de qué aplicaciones estemos utilizando y de lo que estamos tratando de hacer, el resultado puede ser que los cálculos requieran de una gran cantidad de tiempo de la GPU, dejando a la interfaz gráfica de usuario para actualizar sólo en unos cuantos fotogramas por segundo con un desfase significativo.
Para un usuario de NVIDIA, el trazado de rayos del garaje de demostración de tecnología de diseño de NVIDIA es un gran ejemplo de este problema. El vídeo de la derecha muestra como al utilizar el trazado de rayos basado en CUDA afecta gravemente al rendimiento de la visualización (GUI).
Por otra parte, un entorno gráfico con alta capacidad de respuesta significaría que las tareas de cálculo no están recibiendo mucho tiempo para procesar y calcular, y que sólo se ejecutarían en una fracción del rendimiento que el hardware (la tarjeta gráfica Quadro o de computación Tesla) es capaz de realizar.
Por estas razones, si una aplicación tiene que hacer tanto cálculo y como la representación al mismo tiempo, entonces es mejor que lo haga mediante el envío de los cálculos a una GPU dedicada, en este caso a la tarjeta NVIDIA Tesla. Este era el trabajo que anteriormente tenían que realizar los desarrolladores, y un trabajo y una carga para ellos que ahora NVIDIA quiere eliminar con esta tecnología. El propósito final de Maximus™ es permitir que todas las aplicaciones puedan realizar ambas tareas (visualización y cálculos) de una manera eficiente, al trasladar toda la carga de trabajo de los cálculos a otra tarjeta, la NVIDIA Tesla, porque nadie se quiere gastar 4000 € en una Quadro 6000 para que además no sea capaz de realizar todo esto.
Aplicaciones, Demostraciones y Rendimiento.
Las aplicaciones que soportan esta tecnología son todas aquellas que ya utilizaban Quadro y estaban certificadas para estas tarjetas y aquellas que utilizan CUDA para la realización de cálculos complejos (computación). Incluso se podrían añadir aquellas que no están no están certificadas y que utilizan OpenGL como motor gráfico y CUDA para los cálculos.
Todas las aplicaciones de Adobe, ANSYS, Autodesk, Bunkspeed, Dassault Systèmes, MathWorks y un largo etc. que se encuentran en la web de NVIDIA: http://www.nvidia.es/page/workstation.html.
Wil Braithwaite, un ingeniero de NVIDIA, demuestra cómo la nueva tecnología de NVIDIA Maximus™ mejora en gran medida el flujo de trabajo para los profesionales realizando dinámica de fluidos con Autodesk Maya 2012, proporcionando una mejor productividad e interactividad y como se incrementa de forma exponencial la aceleración de partículas con unos resultados impresionantes nunca vistos anteriormente.
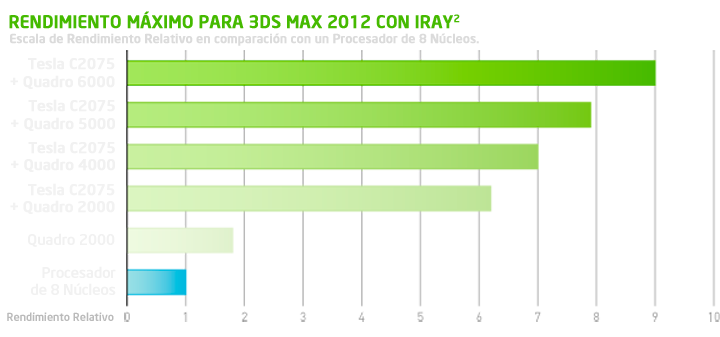
Peter de Lappe, gerente de productos de software de NVIDIA, nos demuestra en el siguiente vídeo (en inglés), cómo la tecnología NVIDIA Maximus™ permite a los usuarios la capacidad de diseñar de forma simultánea en Autodesk Inventor y renderizar Autodesk 3ds Max 2012. Un increíble renderizado interactivo que antes no era posible y que es hasta 9 veces más rápido que un sola CPU.
El siguiente gráfico nos muestra una comparativa del rendimiento máximo de Autodesk 3ds Max 2012 con iRay, con Maximus™ en comparación con un procesador de 8 núcleos:
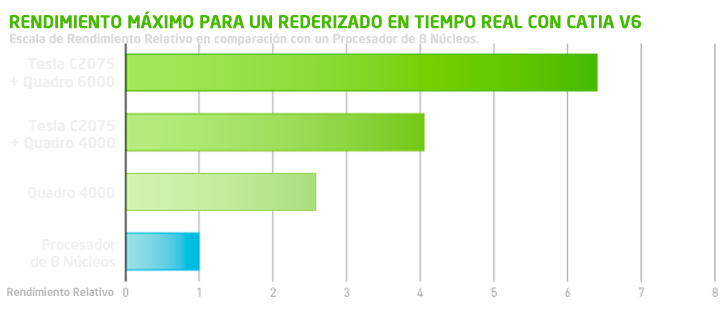
Sam Itskovitch, un ingeniero de aplicaciones de la empresa Dassault Systèmes, demuestra cómo gracias a la nueva tecnología NVIDIA Maximus™ permite a los usuarios realizar renderizados foto realísticos completamente interactivos y prácticamente en tiempo real, con Catia V6.
El siguiente gráfico nos muestra una comparativa del rendimiento máximo con Maximus™ para un renderizado en tiempo real con Catia V6, en comparación con un procesador de 8 núcleos:
Sean Kilbride, director de marketing técnico de NVIDIA, nos demuestra cómo NVIDIA Maximus™ nos permite trabajar más rápido que nunca en la edición de vídeo con Adobe Premiere Pro CS 5.5.2.
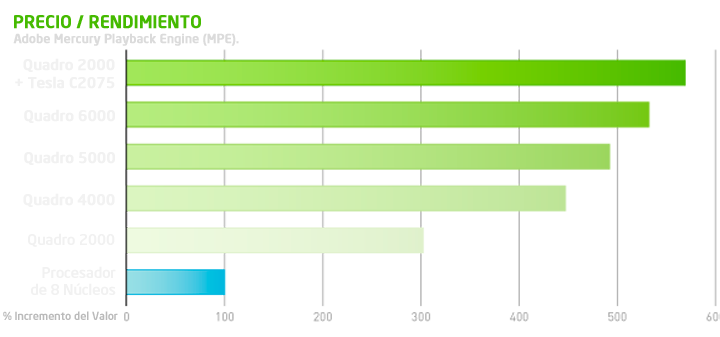
El siguiente gráfico nos muestra una comparativa del precio/rendimiento del motor Adobe Mercury Playback Engine (MPE) con Maximus™, en comparación con un procesador de 8 núcleos:
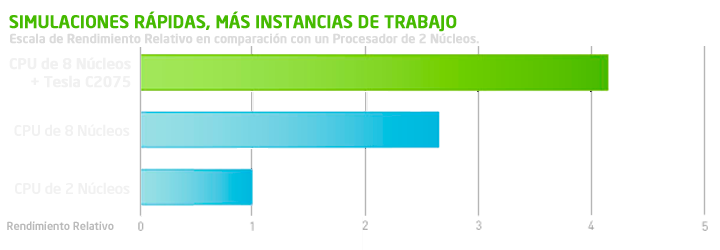
Con la tecnología de NVIDIA Maximus™, se pueden realizar simultáneamente análisis y cálculos de estructuras o de dinámica de fluidos con aplicaciones como ANSYS mientras se ejecuta una aplicación de diseño incluyendo SolidWorks y PCT Creo. El siguiente gráfico nos muestra el rendimiento relativo al realizar simulaciones rápidas con más instancias de trabajo con Maximus™ frente a realizar con un procesador de 2 u 8 núcleos.
Potencia Extrema que elimina la necesidad de granjas de renders.
Con NVIDIA Maximus™ los ingenieros, artistas, diseñadores, científicos pueden ahora interactuar con muy alto rendimiento y potencia visual mientras realizan simulaciones o renderizados. Y todo esto en el mismo sistema y al mismo tiempo. Esto es lo más importante de todo y lo que realmente demuestra toda esta potencia de Maximus™ que merece la pena repetir: interactuar con muy alto rendimiento y potencia visual mientras realizan simulaciones o renderizados en el mismo sistema y al mismo tiempo.
Hay que tener en cuenta que la potencia de toda esta tecnología Maximus™ la podemos ampliar hasta límites insospechados e inimaginables hasta ahora. Porque independientemente del modelo de tarjeta Quadro que estemos utilizando, no solo podemos ampliar el sistema añadiendo una tarjeta Tesla C2075, sino que podemos escalar hasta un total 7 tarjetas Tesla C2075 que es lo máximo que permiten actualmente los sistemas. ¿Se imagina la potencia máxima que tendría un sistema con tarjeta Quadro 6000 con sieta tarjeta Tesla C2075?.
Si partimos de la configuración más simple de Maximus™, una tarjeta Quadro 2000 más una Tesla C2075 estaríamos hablando de una potencia de 515,2 Gflops en coma flotante de doble precisión y de 1.030,4 Gflops en coma flotante de precisión simple.
Y partir de aquí podemos escalar todo lo que queramos hacia arriba. Por ejemplo, una Quadro 4000 con dos tarjetas Tesla C2075 nos daría una potencia de 1.273,6 Gflops en coma flotante de doble precisión y de 2.555,2 Gflops en coma flotante de precisión simple.
Y ya si nos vamos al máximo, una Quadro 6000 con siete tarjetas Tesla C2075 tendríamos una potencia de 4.121,6 Gflops en coma flotante de doble precisión y de 8.275,2 Gflops en coma flotante de precisión simple.
Todos estos datos son realmente impresionantes. Y más aún si tenemos que los superordenadores más grandes del mundo están operando a velocidades de 36,01 Teraflops, como es el caso del superordenador Blue Gene de IBM, o el recien galardona K Computer de Fujitsu como el superordenador más rápido del mundo que ha llegado a alcanzar la friolera de 10,51 Petaflops.

Los programadores y el mercado actual de NVIDIA para las Estaciones de Trabajo.
Vale la pena señalar que esta situación refleja de cerca la situación de los desarrolladores de software. Para propósitos de depuración de software, NVIDIA recomienda a los programadores que tengan dos GPUs, por lo que en una GPU se puede bloquear depurando un cálculo o renderizando una tarea, según sea necesario, mientras que la otra GPU, está disponible para mostrar los resultados. El que NVIDIA anime a los usuarios tener dos GPUs por razones técnicas, no es nuevo, pero se amplía. Significa que hay un camino obvio para moverse hacia un mayor desarrollo como NVIDIA quiere que sea, multitarea entre GPU’s cada vez más cerca e como hoy en día es la multitarea en las CPU’s (procesadores).
 Otra de las razones que NVIDIA quiere conseguir con Maximus™ es el resultado de sus propias acciones. Debido a que la tarjeta Quadro de NVIDIA es el producto líder, una tarjeta Quadro 6000 tiene un precio aproximado es 4.000 € o más. Esto es producto de la segmentación del mercado de NVIDIA bien diseñado, una GPU GF110 puede estar en 500€ en una GTX 580, en 2.300 € en una Tesla C2075 y en 4.000 € en una Quadro 6000. Al desactivar algunas funciones críticas en otros productos (por ejemplo, el rendimiento de la geometría o el soporte FP64) NVIDIA puede empujar a los clientes en la compra de un producto a un precio que NVIDIA cree que es mejor para el mercado objetivo.
Otra de las razones que NVIDIA quiere conseguir con Maximus™ es el resultado de sus propias acciones. Debido a que la tarjeta Quadro de NVIDIA es el producto líder, una tarjeta Quadro 6000 tiene un precio aproximado es 4.000 € o más. Esto es producto de la segmentación del mercado de NVIDIA bien diseñado, una GPU GF110 puede estar en 500€ en una GTX 580, en 2.300 € en una Tesla C2075 y en 4.000 € en una Quadro 6000. Al desactivar algunas funciones críticas en otros productos (por ejemplo, el rendimiento de la geometría o el soporte FP64) NVIDIA puede empujar a los clientes en la compra de un producto a un precio que NVIDIA cree que es mejor para el mercado objetivo.
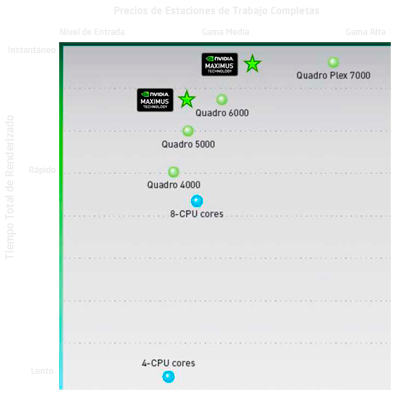
Entonces, ¿cuál es el problema? La Quadro 6000 es tanto un producto con una alta capacidad de renderizado como un producto con una alta capacidad de cálculo (computación), pero que no todos los usuarios profesionales necesitan tanta potencia de renderizado incluso aunque necesiten un producto con tanta potencia de cálculo. Estos usuarios seguirán necesitando una tarjeta Quadro por su rendimiento sin límites ni bloqueos en renderizados pero no necesitan necesariamente algunas de las características de la Quadro 6000 como el rendimiento de la geometría masivo. El resultado es que NVIDIA estaba marcando precios fuera de su propio mercado y de los segmentos que tiene establecidos, como muestra la imágen de la derecha.
La solución a todo esto es la combinación de Quadro y Tesla. Maximus™ permite una o más tarjetas Tesla C2075 para ser utilizadas con cualquier tarjeta basada en Quadro Fermi (600/2000/4000/5000/6000), que permite a NVIDIA ajustar más adecuadamente el mercado solapado de los usuarios de Quadro que necesitan de un alto nivel de rendimiento en cálculos (computación). El resultado final para los usuarios no es solo que les cueste menos, una Quadro 2000 más una Tesla C2075 cuesta aproximadamente 2.750 € en comparación con los más de 4.000 € que cuesta una Quadro 6000, sino que además ganan las ventajas antes mencionadas de no tener tareas en conflicto al ralentizar el rendimiento de una única tarjeta Quadro. Es cierto que este es un gran esfuerzo por parte de NVIDIA para aprovechar un mercado muy específico, pero al final, el resultado es que el mercado profesional es un mercado muy rentable, por lo que vale la pena el tiempo de NVIDIA.
Conclusión.
Los avances en este sector en estos últimos años dejan bastante claro que este el futuro del mercado de los profesional de la visualización, edición, creación, animación, etc. Desde que NVIDIA inventó, definió y popularizo lo que hoy conocemos como GPU en el año 1.999, los constantes avances y desarrollos entorno a esta tecnología no han parado. Y no solo no han parado, sino que día tras día crece cada vez más rápidamente.
En los inicios de la GPU, al descubrir la gran capacidad y potencia que tenían estos procesadores así como sus nuevas capacidades para cálculo, comenzaron a desarrollarse tecnologías como transformaciones gráficas integradas, técnicas de iluminación, motores de renderizado y así un largo etcétera, cuyas aplicaciones y desarrollos iniciales estaban únicamente enfocadas a los juegos.
Pero a medida que iba creciendo todo este potencial con nuevos desarrollos y viendo las velocidades que las GPU's alcanzaban en el procesamiento y cálculos en paralelo, comenzó poco a poco a extenderse su uso a nivel profesional, primero de la mano de NVIDIA con el desarrollo de sus tarjeta Quadro, y más adelante con el apoyo de Autodesk con su aplicaciones como AutoCAD y 3ds Max, y poco a poco se han ido uniendo más y más compañías como recientemente Adobe con su nuevo motor Adobe Mercury Playback Engine en su versión CS5.
En estos dos últimos años hemos visto como toda esta tecnología profesional ha quedado asentada y definida en una plataforma y un entorno bastante sólido. Todas las presentaciones de las últimas versiones de las aplicaciones profesionales se han presentado con soporte para estas tecnologías aquellas que no las tenían ya, o con considerables mejoras en este aspecto aquellas que ya las tenían. Hace exactamente un año, en noviembre de 2010, Chaos Group presentaba su aplicación para trazado de rayos V-Ray, y su principal característica era el apoyo y el soporte GPU para renderizar, que no tenían las versiones anteriores, consiguiendo realizar los renderizados en menos de 10 veces de la mitad de tiempo.
Ante todo este claro avance que acabamos de explicar, y con el apoyo de NVIDIA y de todas las empresas más importantes de aplicaciones y programas de este sector queda claro que esta tecnología es el futuro de todo este sector profesional y que esta tecnología, muy lejos de quedarse estancada o desaparecer, va a ir creciendo de forma impresionantemente exponencial como ya hemos ido viendo en estos últimos más de 10 años. Y de momento pensamos que todo lo que estamos viendo y explicando de esta tecnología es solo el principio y el comienzo de todo lo que está por llegar.
Porque hablamos de apoyos a esta tecnología de empresas como Autodesk, Adobe, Dassault Systèmes, Siemens, ANSYS, MathWorks, Bunkspeed, etc. y de importantes empresas que ya están están utilizando estas tecnologías como Mercedes Benz, NASA, Astrobotic Technology y muchísimas más, así como las principales empresas de efectos especiales para los principales estudios de cine con desarrollos en películas como Avatar, etc. Sirva como ejemplo el siguiente y gracioso vídeo de "Los Teleñecos". Son los mismos teleñecos de siempre pero en esta ocasión están más y mejor animados gracias a la animación por ordenador utilizando tarjetas gráficas NVIDIA Quadro y Tesla por parte de la empresa de animación Look Effects.
Hoy con Maximus™ llegamos a unos límites con toda esta tecnología que nunca antes se había llegado y que era impensable llegar. Un impresionante avance y un rendimiento en una sola estación de trabajo inimaginables hasta la fecha. Muchos podrán pensar que con esta tecnología hemos llegado al máximo en este campo y en este sector de la visualización, pero como decíamos antes, esto es solo el principio.
NVIDIA ha dejado claro que va a estar empujando a Maximus™ al máximo. En estos días fue también el lanzamiento de la plataforma Sandy Bridge E de Intel para gama alta de equipos de sobremesa y estaciones de trabajo, y en esta industria hay muy pocas coincidencias. Es en el interés de NVIDIA de actualizar las ventas de estaciones de trabajo, y es así como lo hace.
Ya se han alineado con NVIDIA fabricantes como HP, Lenovo, Fujitsu y Dell para ofrecer puestos de trabajo pre-configurados para Maximus™, y por supuesto en MANTIS Informática llevamos más de un año ofreciendo equipos disponibles compatibles con esta tecnología a pesar de no estar disponible, ya que nuestras estaciones de trabajo están configuradas con opciones de tarjeta Quadro más una, dos o tres tarjetas Tesla. Cualquiera que haya podido visitar nuestra oferta de estaciones de trabajo desde hace un año verá que en nuestra web existen modelos específicos con todas estas configuraciones. Ahora con este nuevo controlador unificado para Quadro y Tesla gracias a Maximus™, estas estaciones de trabajo amplían su capacidad, potencia y rendimiento muy considerablemente al obtener soporte para todas las aplicaciones que antes no lo tenían.
En cuanto a si Maximus™ tendrá éxito o no, esto va a depender tanto del software como de la estrategia y marketing en la comercialización. En cuanto al software NVIDIA tiene que cumplir con la transparencia Maximus™ promete a los desarrolladores y a los usuarios. Aunque el concepto es simple, para el mercado profesional la ejecución del mismo y de lo que prometen debe ser precisa. La tecnología Optimus™ de los portátiles, falla de vez en cuando realizando el cambio de tarjeta gráfica entre la nVidia Geforce y la de Intel IGP integrada en el procesador, pero los usuarios profesionales no estarán tan dispuestos a soportar cualquier comportamiento indeseado con Maximus™.
Por otro lado, NVIDIA trata por igual el marketing promocional de Maximus™ que el promocional de CUDA. Una gran cantidad de material promocional de NVIDIA para Maximus™ podría ser fácilmente confundido con el material de promoción de CUDA, y esto se debe a que los videos y los casos de estudio son en gran parte sobre cómo CUDA mejora un proceso o un producto, mientras que Maximus™ es la guinda del pastel. El problema es que gran parte del mercado profesional que NVIDIA tiene como objetivo aún no ha oído hablar en su vida de CUDA, o tiene un conocimiento limitado en el mejor de los casos. Como tal NVIDIA va a utilizar el lanzamiento de Maximus™ para promover los beneficios de CUDA para ciertos mercados específicos, tales como la fabricación, el diseño la televisión o difusión de vídeo, etc. cuando en realidad tendría que promocionar los beneficios de tener múltiples GPUs.
Jordi
publicado el jueves 17 de octubre de 2013 10:41:33 Europe/Paris